News Releases
Mitsubishi Electric Develops Scene-Aware Interaction Technology More natural and intuitive human-machine interaction through scene awareness
FOR IMMEDIATE RELEASE No. 3365
TOKYO, July 22, 2020 - Mitsubishi Electric Corporation (TOKYO: 6503) announced today that the company has developed what it believes to be the world's first technology capable of highly natural and intuitive interaction with humans based on a scene-aware capability to translate multimodal sensing information into natural language. The novel technology, Scene-Aware Interaction, incorporates Mitsubishi Electric's proprietary Maisart®* compact AI technology to analyze multimodal sensing information for highly natural and intuitive interaction with humans through context-dependent generation of natural language.
The technology recognizes contextual objects and events based on multimodal sensing information, such as images and video captured with cameras, audio information recorded with microphones, and localization information measured with LiDAR. To prioritize these different categories of information, Mitsubishi Electric developed the Attentional Multimodal Fusion technology, which is capable of automatically weighting salient unimodal information to support appropriate word selections for describing scenes with accuracy. In benchmark testing using a common test set, the Attentional Multimodal Fusion technology used audio and visual information to achieve a Consensus-Based Image Description Evaluation (CIDEr)** score that was 29 percentage points higher than in the case of using visual information only. Mitsubishi Electric's combination of Attentional Multimodal Fusion with scene understanding technology and context-based natural language generation realizes a powerful end-to-end Scene-Aware Interaction system for highly intuitive interaction with users in diverse situations.
- * Mitsubishi Electric's AI creates the State-of-the- ART in technology

- **CIDEr is an evaluation metric that measures the similarity of a generated sentence against a set of ground-truth sentences written by humans, placing importance on word sequences that are used relatively frequently by humans.
Scene-Aware Interaction for car navigation, one target application, will provide drivers with intuitive route guidance. For instance, rather than instructing the driver to "turn right in 50m," the system would instead provide scene-aware guidance, such as "turn right before the postbox" or "follow that gray car turning right." Furthermore, the system will generate voice warnings, such as "a pedestrian is crossing the street," when nearby objects are predicted to intersect with the path of the car. To achieve this functionality, the system analyzes scenes to identify distinguishable, visual landmarks and dynamic elements of the scene, and then uses those recognized objects and events to generate intuitive sentences for guidance.
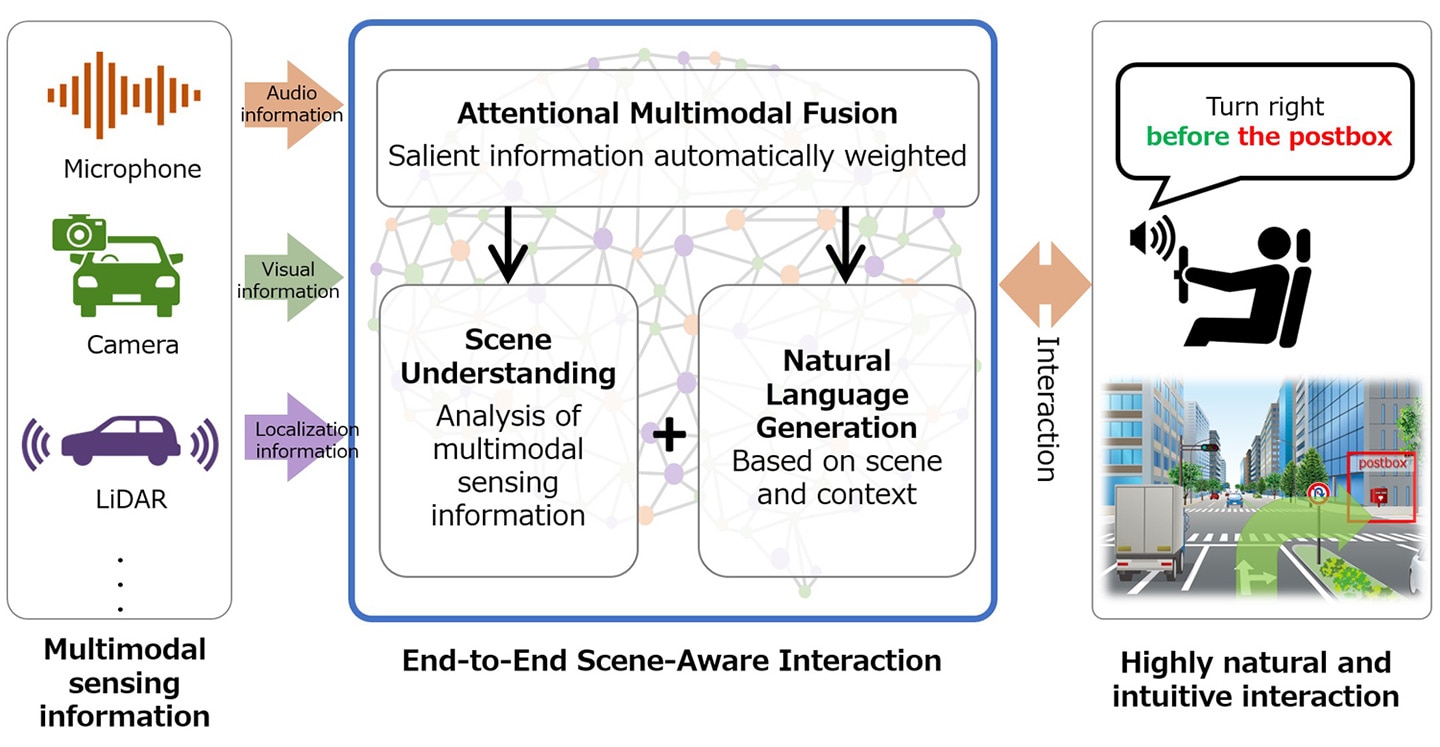
Recent advances in object recognition, video description, natural language generation and spoken dialog technologies using deep neural networks are enabling machines to better understand their surroundings and interact with humans more naturally and intuitively. Scene-Aware Interaction technology is expected to have wide applicability, including human-machine interfaces for in-vehicle infotainment, interaction with robots in building and factory automation systems, systems that monitor the health and well-being of people, surveillance systems that interpret complex scenes for humans and encourage social distancing, support for touchless operation of equipment in public areas, and much more.
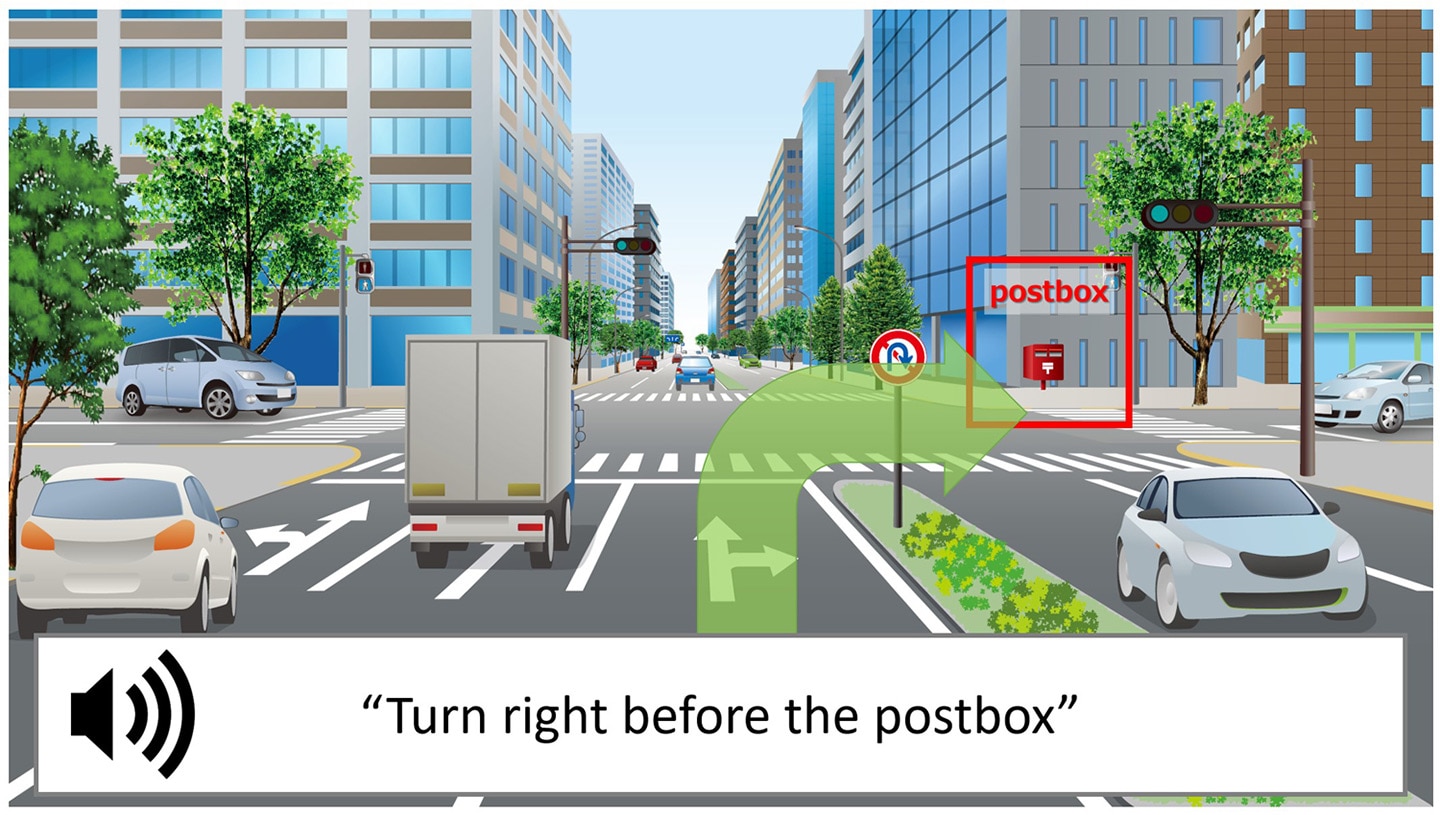
Example of Scene-Aware Interaction providing contextual guidance

Example of Scene-Aware Interaction providing guidance to avoid hazards
Note
Note that the press releases are accurate at the time of publication but may be subject to change without notice.



