بالنسبة للنشرة الفورية رقم ٣١١٢
إن هذا النص ترجمة للنص الإنجليزي الرسمي لهذا الإصدار الجديد، وقد تم تزويده للرجوع إليه بسهولة عند الحاجة. يرجى الرجوع إلى النص الإنجليزي الأصلي للحصول على التفاصيل و/أو المواصفات الخاصة. في حال وجود أي تعارض، فيجب اتباع محتوى الإصدار الإنجليزي الأصلي.
Mitsubishi Electric تتمكن من فصل الكلام المتزامن المسجل بميكروفون واحد لعدة متحدثين غير معروفين
تحققت تقنية فصل الكلام من خلال طريقة مُسجلة الملكية تعتمد على الذكاء الاصطناعي (AI) وتُعرف باسم "التجميع المتعمق"
طوكيو، ٢٤ مايو، ٢٠١٧ - أعلنت شركة Mitsubishi Electric Corporation (طوكيو: ٦٥٠٣) اليوم أنها قد ابتكرت التقنية الأولى في العالم لفصل الكلام المتزامن المسجل بميكروفون واحد من قِبل متحدثين متعددين غير معروفين ثم إعادة بنائه بجودة عالية في الوقت الحقيقي. وأثناء الاختبارات، تم فصل الكلمات المتزامنة الصادرة عن شخصين أو ثلاثة أشخاص بدقة تصل نسبتها إلى ٩٠ و٨٠ بالمئة، على التوالي، وتعتقد الشركة أن هاتين النسبتين هما الأولتان في العالم وقت صدور هذا الإعلان. إن التقنية الجديدة، التي تحققت من خلال طريقة "التجميع المتعمق" المسجلة ملكيتها لشركة Mitsubishi Electric والتي تعتمد على الذكاء الاصطناعي (AI)، من المتوقع أن تسهم في تحقيق اتصالات صوتية أكثر وضوحًا والتعرف التلقائي على الكلام بشكل أكثر دقة.
في حالة تحدث شخصين في وقت واحد، تخطت نسبة الدقة ٩٠ بالمئة، وتعتبر كافية للاستخدامات التجارية، بالمقارنة مع دقة بنسبة ٥١ بالمئة عند استخدام التقنية التقليدية. بإمكان التقنية الجديدة التمييز بين مجموعات من لغات عديدة منطوقة وتمييز نوع المتحدث. وتعتمد النتائج الواردة بالأعلى على حالات تسجيل مثالية، بما فيها الضوضاء المحيطة المنخفضة والأشخاص الذين يتحدثون بمستوى صوت مماثل تقريبًا.
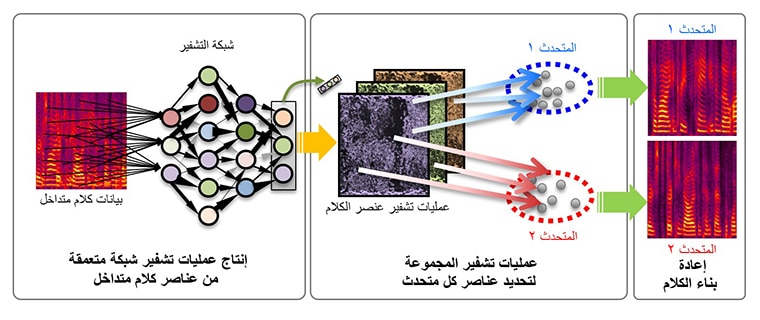
إن تقنية "التجميع المتعمق" تستخدم طريقة التعلم المتعمق المسجلة ملكيتها لشركة Mitsubishi Electric لتتعرف على كيفية تشفير مكونات الإشارة الخاصة ببيانات الكلام الأصلي لعدة أشخاص حتى يمكن تمييز مكونات الإشارة الخاصة بكل متحدث فردي بسهولة من خلال الشفرات الخاصة بهذه المكونات. ولتحقيق ذلك، تم تحسين الشفرات بحيث تكون لدى مكونات الإشارة المختلفة الخاصة بالمتحدث نفسه شفرات مماثلة بينما تكون لدى الأخرى الخاصة بمتحدثين مختلفين شفرات مختلفة. يتم تطبيق تحويل التشفير المتعلَّم على كلام المدخل، ويتم تحديد شفرات مكونات الإشارة الخاصة بكل متحدث باستخدام خوارزمية تجميع، والتي تقوم بمعالجة نقاط البيانات بحيث يتم تجميع تلك النقاط في مجموعات وفقًا لتماثلها. وبعد ذلك تتم إعادة بناء الكلام الخاص بكل شخص من خلال إعادة تجميع مكونات الكلام المنفصلة الخاصة به.
الدقة في فصل كلام متزامن لمتحدثين متعددين*
| متحدثان (ميكروفون واحد) | ثلاثة متحدثين (ميكروفون واحد) | |
|---|---|---|
| التقنية الجديدة | أكثر من ٩٠% (الأولى في العالم) | أكثر من ٨٠% (الأولى في العالم) |
| التقنية التقليدية | ٥١% | ─ |
*بناءً على ظروف تسجيل مثالية
تجدر الإشارة إلى أن النشرات الإخبارية دقيقة في وقت نشرها لكنها قد تكون عرضة للتغيير من دون إشعار.
الاستفسارات
- جهة الاتصال الإعلامية
- قسم العلاقات العامة بشركة Mitsubishi Electric(Open new window)
- استفسارات العملاء
- معامل الأبحاث بشركة Mitsubishi Electric(Open new window)